What is AWS SageMaker?
AWS SageMaker is a fully-managed service for machine learning in the cloud. It lets you build and train machine learning models, directly deploying them into a production-ready, hosted environment. SageMaker aims to simplify machine learning work, providing various features, including:
- Jupyter notebooks—SageMaker provides an integrated Jupyter notebook authoring instance. It offers easy access to data sources for exploration and analysis. There is no need to manage servers.
- Machine learning algorithms—SageMaker provides common machine learning algorithms optimized to run against large data in a distributed environment. It also lets you use your own frameworks and algorithms, offering flexible distributed training capabilities that can adjust to specific workflows.
You can use the SageMaker console or SageMaker Studio to deploy a machine learning model into a scalable and secure environment.
In this article:
How Does Amazon SageMaker Work?
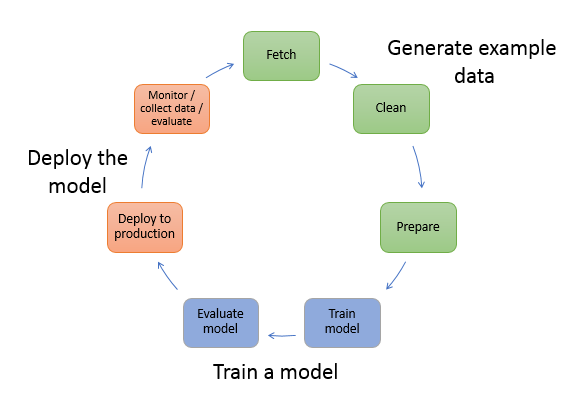
AWS SageMaker uses a three-step machine learning modeling process that incorporates preparation, training, and deployment. Here is a diagram that illustrates a typical workflow for creating a machine learning model:

Prepare and Build AI Models
The first step in SageMaker's machine learning modeling workflow is preparation. SageMaker creates a fully-managed machine learning instance in Amazon EC2 and runs Jupyter computational processing notebooks to support this phase.
Notebooks
Jupyter Notebook is an open source web application that enables you to share live code. Notebooks include packages, drivers, and libraries for common deep learning frameworks and platforms. SageMaker lets you launch prebuilt notebooks supplied by AWS for various use cases or customize notebooks for a specific dataset and schema.
Data
SageMaker supports Amazon Simple Storage Service (S3) and can pull a massive amount of data. It does not place limitations on the size of the dataset.
Algorithms
SageMaker lets you import custom algorithms written using a supported machine learning framework or code packaged as a Docker container image. It also provides built-in training algorithms, including image classification and linear regression.
Console
You can start working on your machine learning model by logging into the SageMaker console and launching a notebook instance.
Train and Tune
This step involves transforming data for feature engineering. SageMaker lets you define the data's location in an S3 bucket and specify a preferred instance type. Once you specify this information, you can initiate the training process. Next, SageMaker Model Monitor performs continuous automatic model tuning. It looks for the set of parameters or hyperparameters that can best optimize your algorithm.
Deploy and Analyze
This phase involves deploying the machine learning model, analyzing it, and fine-tuning it with new data to increase its accuracy.
Deploy
Once your machine learning model is ready for deployment, SageMaker automatically operates and scales the underlying cloud infrastructure using a set of SageMaker instance types. These types include several graphics processing unit (GPU) accelerators optimized for machine learning workloads.
Here are key tasks performed by SageMaker:
- Deploys your model across multiple availability zones (AZ)
- Performs routine health checks
- Applies security patches
- Configures AWS Auto Scaling
- Establishes secure HTTPS endpoints
You can use Amazon CloudWatch metrics to track this process and set up trigger alarms indicating changes in production performance.
Analyze
Ideally, machine learning modeling should be a continuous cycle. After deployment, you need to monitor the inferences, collect "ground truth," and identify drift by evaluating the model. Next, you retrain the model with the new dataset to update the training data with the new ground truth. This process repeats—when there is more example data, you continue retraining the model to increase its accuracy.
AWS SageMaker Model Training
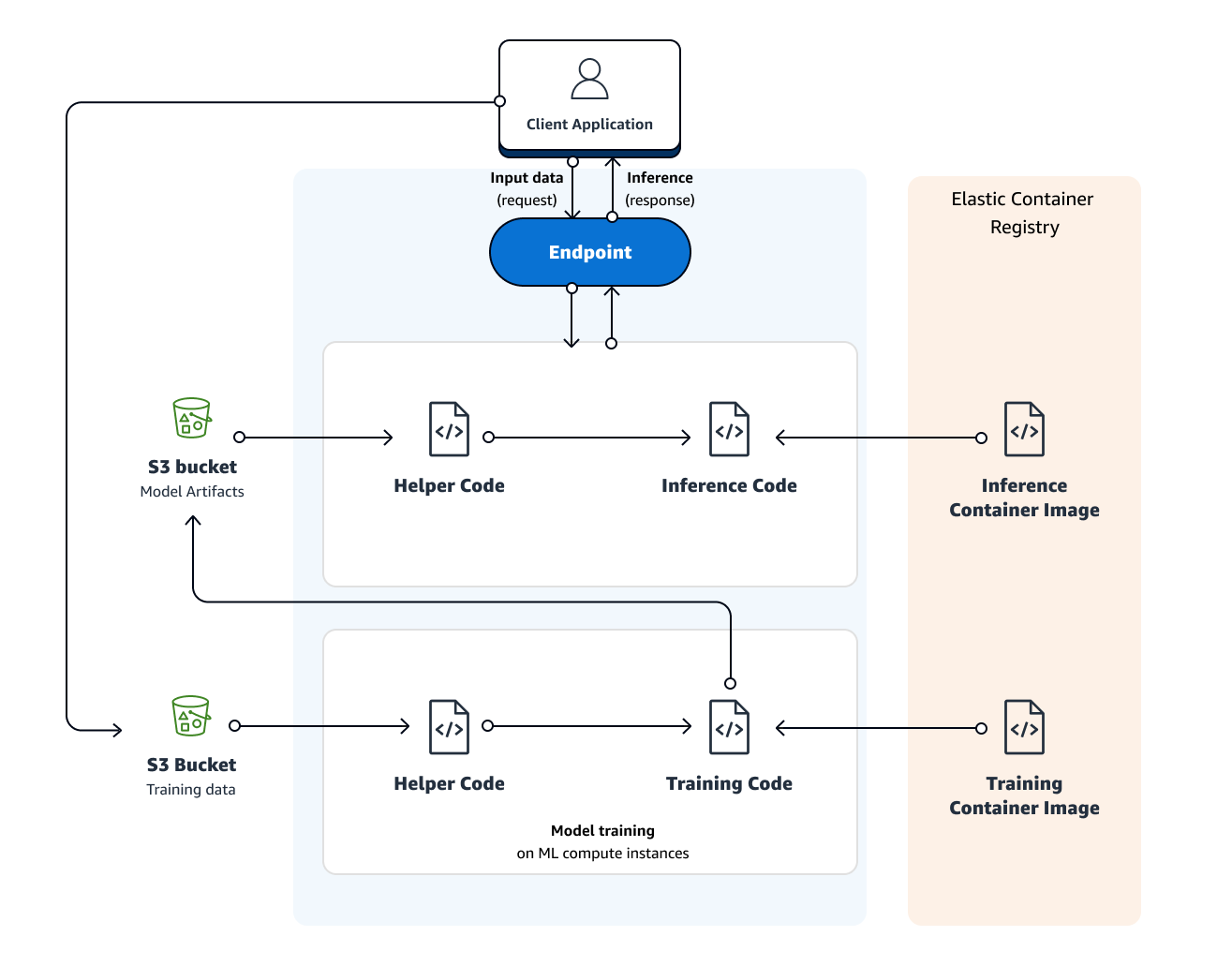
Here is a diagram that illustrates the model training and deployment process with AWS SageMaker:

You can train a model in SageMaker by creating a training job. Each training job needs to include the following information:
- Training data storage—specify the URL of the Amazon S3 bucket that stores your training data.
- Compute resource—specify the required compute resources for model training. A compute resource is a machine learning compute instance managed by SageMaker.
- Output storage—specify the URL of the desired S3 bucket for storing the job's output.
- Training code—specify the Amazon Elastic Container Registry path storing your training code.
SageMaker lets you use various training algorithm options, including:
- SageMaker algorithms—SageMaker offers ready-made training algorithms that you can use instead of creating your own algorithms from scratch.
- SageMaker Debugger—you can use this tool to inspect training parameters and data across the training process. It supports TensorFlow, Apache MXNet, and PyTorch learning frameworks, and the XGBoost algorithm. This tool can automatically detect and alert on frequently occurring errors.
- Apache Spark with SageMaker—SageMaker offers a library to use in Apache Spark for training models with SageMaker.
- Custom code—SageMaker lets you submit custom Python code using deep learning frameworks like TensorFlow, Apache MXNet, and PyTorch for model training.
- Custom algorithms—SageMaker lets you package your code as a Docker image and define a registry path for the image in a SageMaker CreateTrainingJob API call.
- AWS Marketplace algorithms—SageMaker lets you use an algorithm from AWS Marketplace.
Once you create a training job, SageMaker launches machine learning compute instances. Next, it uses your training code and dataset to train the model. SageMaker saves all resulting model artifacts and any other output in a predefined S3 bucket.
Quick Tutorial: Getting Started with SageMaker JumpStart
SageMaker JumpStart lets you discover SageMaker with a set of turnkey solutions, notebook examples, and deployable pre-trained models. You can also fine-tune and deploy models. You can access JumpStart through Amazon SageMaker Studio or programmatically via the SageMaker API.
Open JumpStart using the JumpStart launcher in the Getting Started section or by selecting the JumpStart icon in the left sidebar. JumpStart opens in a new tab in the main workspace. You can also use the search bar at the top of the JumpStart page to find topics that interest you.

When you deploy a model in JumpStart, SageMaker immediately deploys an endpoint that hosts the model and can be used for inference. JumpStart also provides sample notebooks you can use to access your models after they are deployed.
When you select a model, the Deploy Model screen appears. Expand Deployment Configuration to define model settings.

The settings are shown below. Each model runs with a default SageMaker instance type that provides the necessary computing resources, but you can choose to run with a different instance size. You can also configure the endpoint name.

Machine Learning Resource Orchestration with Run:ai
When using AWS SageMaker, your organization might run a large number of machine learning experiments requiring massive amounts of computing resources. Run:ai automates resource management and orchestration for machine learning infrastructure. With Run:ai, you can automatically run as many compute intensive experiments and inference workloads as needed.
Here are some of the capabilities you gain when using Run:ai:
- Advanced visibility—create an efficient pipeline of resource sharing by pooling GPU compute resources.
- No more bottlenecks—you can set up guaranteed quotas of GPU resources, to avoid bottlenecks and optimize billing.
- A higher level of control—Run:ai enables you to dynamically change resource allocation, ensuring each job gets the resources it needs at any given time.
Run:ai simplifies machine learning infrastructure pipelines, helping data scientists accelerate their productivity and the quality of their models.
Learn more about the Run:ai GPU virtualization platform.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}