What Is AWS Sagemaker Model Deployment?
Amazon SageMaker is a managed service that provides developers and data scientists the ability to build, train, and deploy machine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process, making it easier to develop high-quality models. It provides a broad set of capabilities, such as preparing and labeling data, choosing an algorithm, training and tuning a model, and deploying it to make predictions.
AWS SageMaker Model Deployment, part of the SageMaker platform, provides a solution for deploying machine learning models with support for several types of inference: real-time, serverless, batch transform, and asynchronous. It also provides advanced features like serving multiple models on a single endpoint, and serial inference pipelines, which are multiple containers executing machine learning operations in a sequence.
SageMaker Model Deployment can support any scale of operation, including models that require rapid response in milliseconds or need to handle millions of transactions per second. It also integrates with SageMaker MLOps tools, making it possible to manage models throughout the machine learning pipeline.
This is part of a series of articles about machine learning inference.
In this article:
AWS Sagemaker Inference Options
Real-Time Inference
Real-Time Inference allows users to obtain predictions from their machine learning models in real-time. This is particularly useful for applications that need to respond to events as they happen.
For instance, a fraud detection system might use real-time inference to identify fraudulent transactions as they occur. Real-Time Inference can also be used to personalize user experiences on the fly. For instance, a streaming service might use real-time inference to recommend new shows or movies to a user based on their viewing history.
Serverless Inference
Serverless Inference is another option offered by AWS Sagemaker Inference. With this option, you don't have to worry about managing servers or scaling your applications. AWS handles all of this for you, allowing you to focus on developing your machine learning models.
Serverless Inference can be particularly useful for applications with variable workloads. For instance, a retail business might see a surge in traffic during the holiday season. With Serverless Inference, the business can easily handle this increased traffic without having to provision additional resources.
Batch Transform
Batch Transform is an AWS Sagemaker Inference option that allows users to process large volumes of data in batches. This can be useful for applications that don't need real-time predictions.
For instance, a business might use Batch Transform to analyze their sales data at the end of each day. Batch Transform can also be used to pre-process large volumes of data before feeding it into a machine learning model. This can help improve the performance of your models, as they can be trained on clean, well-structured data.
Asynchronous Inference
Asynchronous Inference is an AWS Sagemaker Inference option that enables users to make requests for predictions and receive the results later. This can be beneficial for applications that can afford to wait for the results. For instance, an application might use Asynchronous Inference to analyze user behavior over time.
How to Use AWS Sagemaker Model Deployment for Inference
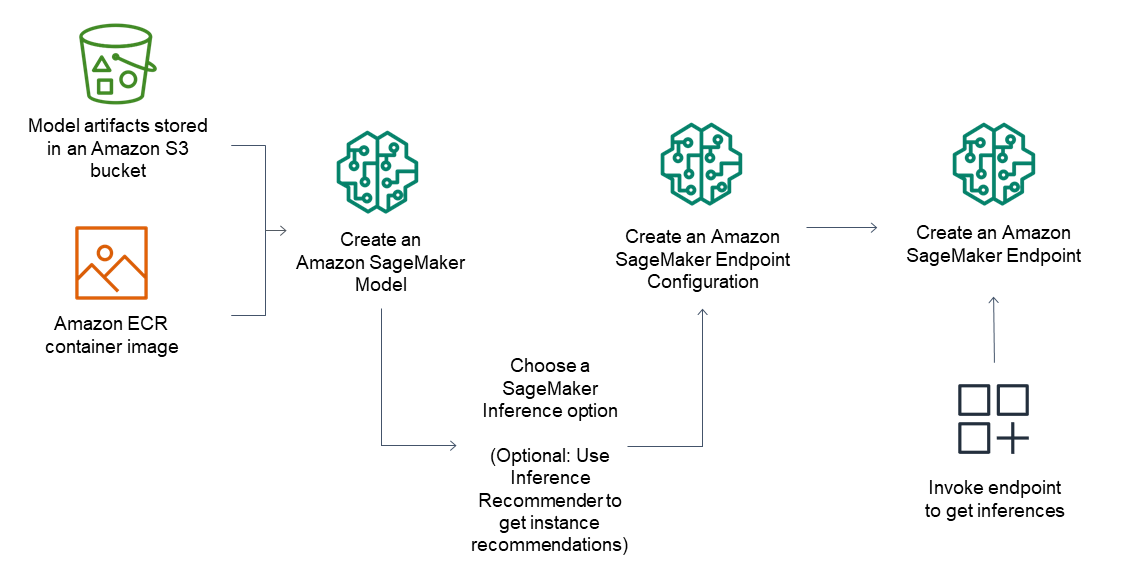
The deployment of models for inference tasks using AWS Sagemaker involves several steps as listed below:
- Create a model in SageMaker Inference. This should point to your model artifacts stored in Amazon S3 and a container image.
- Choose an inference option. Additional information about these options is available.
- Set up a SageMaker Inference endpoint configuration. For this step, you need to decide on the type of instance and the number of instances you need to run behind the endpoint. To make an informed decision, you can use the Amazon SageMaker Inference Recommender that offers suggestions based on the size of your model and your memory requirements. In the case of Serverless Inference, the only requirement is to provide your memory configuration.
- Create an endpoint in SageMaker Inference.
- Invoke your endpoint to receive an inference as a response.
The sequence of operations is shown in the diagram below.

Performing these actions can be done through various AWS platforms such as the AWS console, the AWS SDKs, the SageMaker Python SDK, AWS CloudFormation, or the AWS CLI.
In regards to batch inference with the batch transform, you need to point to your model artifacts and input data, and then establish a batch inference job. Unlike hosting an endpoint for inference, Amazon Sagemaker outputs your inferences to a designated Amazon S3 location.
Best Practices to Improve Your SageMaker Inference Workflow
Use Model Monitor to Track Model Metrics Over Time
One of the critical aspects of managing machine learning models is monitoring their performance over time. Models can experience drift, as the data they were trained on becomes less relevant, or the environment changes. This is where SageMaker Model Monitor comes in.
The Model Monitor provides detailed insights into your model's performance using metrics. It tracks various aspects like input-output data, predictions, and more, allowing you to understand how your model is performing over time. This helps make informed decisions about when to retrain or update your models.
Additionally, with the Model Monitor, you can set up alerts to notify you when your model's performance deviates significantly from the established baseline
Use SageMaker MLOps to Automate Machine Learning Workflows
Automation is crucial for efficient machine learning operations, and AWS SageMaker MLOps provides tools for automating various stages of the ML workflow. This includes everything from data preparation and model training to deployment and monitoring. With MLOps, you can streamline your workflow, reduce manual errors, and ensure that your models are always up-to-date with the latest data.
SageMaker MLOps integrates with CI/CD pipelines and version control systems, enabling automated model training and deployment. You can set up pipelines that automatically retrain and deploy your models based on new data or code changes. This ensures that your models are continuously improved and that your applications are using the most accurate and relevant predictions.
Use an Inf1 instance Real-Time Endpoint for Large Scale Models
Inf1 instances are powered by AWS Inferentia chips, designed specifically for machine learning inference tasks. They offer high performance at a low cost, making them ideal for large scale applications.
In addition, you can use a real-time endpoint with your Inf1 instance. This allows you to make inference requests to your models in real-time, which is especially useful for applications that require immediate predictions. By leveraging Inf1 instances and real-time endpoints, you can run your large-scale applications more efficiently and cost-effectively.
Use SageMaker’s Pre-Built Models to Optimize Inference Performance
AWS SageMaker offers a collection of pre-built models that are optimized for various inference tasks. These models can significantly speed up the deployment process and improve inference performance. By using pre-built models, you can avoid the time and resources required to develop and train a model from scratch.
These pre-built models cover a wide range of applications, such as image and video analysis, natural language processing, and predictive analytics. They are optimized for performance on AWS infrastructure, ensuring fast and efficient inference. Additionally, you can customize these models with your own data to better fit your specific use case.
Inference Optimization with Run:ai
Run:ai automates resource management and orchestration for machine learning infrastructure, including expert systems and inference engines. With Run:ai, you can automatically run as many compute intensive experiments as needed.
Here are some of the capabilities you gain when using Run:ai:
- Advanced visibility—create an efficient pipeline of resource sharing by pooling GPU compute resources.
- No more bottlenecks—you can set up guaranteed quotas of GPU resources, to avoid bottlenecks and optimize billing.
- A higher level of control—Run:ai enables you to dynamically change resource allocation, ensuring each job gets the resources it needs at any given time.
Run:ai simplifies machine learning infrastructure pipelines, helping data scientists accelerate their productivity and the quality of their models.
Learn more about the Run:ai GPU virtualization platform.


{kind=link}